Pipeline su Gitlab per il deploy automatico di Hugo
Nell’articolo in cui ti ho spiegato come installare Hugo e avviare un nuovo progetto, non ho parlato del deploy.
Rimediamo subito!!
Dopo aver creato il progetto, scelto il template e inserito i primi contenuti avrai sicuramente l’esigenza di generare il codice HTML e caricare il tuo sito su un servizio di hosting per renderlo pubblico. Recati quindi con il terminale nella cartella del tuo progetto e digita il comando:
antonio@xps14:~/Documenti/dev/progressify$ hugo
| EN
-------------------+------
Pages | 113
Paginator pages | 4
Non-page files | 0
Static files | 496
Processed images | 0
Aliases | 53
Sitemaps | 1
Cleaned | 0
Total in 444 ms
Automaticamente verrà creata la cartella public con al suo interno i file HTML pronti da caricare sul tuo spazio
hosting, puoi fare l’upload via FTP.
Sono dei passaggi molto semplici, sicuramente… Ma, prova ad immaginare un attimo la situazione: ad ogni aggiornamento del tuo sito devi, manualmente, generare i file HTML con il comando che ti ho indicato e caricarli via FTP. Magari all’inizio, se il tuo sito ha pochi contenuti, questa operazione potrebbe richiedere non più di 5 min. Ma 5 minuti sono comunque tanti, senza contare il fatto che, con il passare del tempo, il sito potrebbe aumentare di dimensioni ed impiegare più tempo per la fase di upload.
Tutto ciò che è automatizzabile DEVE essere automatizzato!!
Come puoi intuire dal titolo, per automatizzare il deploy ho scelto di utilizzare Gitlab, il motivo è molto semplice: non conosco ancora per bene come funzionano le action di Github, ma conosco abbastanza le pipeline di Gitlab e a prima vista mi sembrano molto più elastiche rispetto alla controparte.
Piccola introduzione su cosa sono le pipeline di Gitlab
Una pipeline è una sequenza di operazioni che vengono eseguite sul codice presente nel repository, allo scatenarsi di un evento. Le operazioni della pipeline vengono eseguite una dopo l’altra, nell’ordine in cui sono state definite, mai in parallelo, se una singola operazione non va buon fine tutta la pipeline fallisce e termina con un errore. Se una pipeline fallisce, Gitlab ti avvisa con una mail.
Gitlab ci consente di controllare in tempo reale quale operazione sta svolgendo una pipeline e di visualizzare il log. Conserva inoltre lo storico di tutte le pipeline eseguite, i messaggi di errore nel caso in cui qualcosa fosse andato storto ed i relativi artefatti pronti per essere scaricati.
Una delle feature davvero interessanti è la possibilità di scegliere un’immagine docker, direttamente dal dockerhub, per ogni operazione della pipeline, così da avere già a disposizione diversi ambienti preconfigurati per fare le build o eseguire test, etc.
Vediamo come si configura una pipeline
Per configurare una pipeline su Gitlab devi creare un file con nome .gitlab-ci.yml nella root del tuo progetto.
Questa è la pipeline completa del deploy per il mio sito web.
# Magic deploy of my site
# Antonio Porcelli
# progressify.dev
---
stages:
- build
- deploy
build:
stage: build
image: jojomi/hugo
script:
- hugo version
- git submodule update --init --recursive
- hugo -d public_html --gc --minify
artifacts:
paths:
- public_html
only:
- master
deploy:
stage: deploy
image: alpine
before_script:
- apk update
- apk add lftp
script:
- lftp -e "set ftp:ssl-allow no; open $FTP_HOST; user $FTP_USER $FTP_PASSW; mirror -X .* -X .*/ --reverse --verbose --delete public_html/ ./; bye"
only:
- master
Fai molta attenzione all’indentazione del file, devi rispettare la sintassi yaml.
Le righe che iniziano con # sono commenti. Nella prima parte della pipeline ho definito gli stages, in pratica vado
a definire quali sono gli step che deve effettuare:
stages:
- build
- deploy
quindi questa pipeline effettuerà una prima operazione di build del progetto Hugo ed una seconda parte di deploy,
cioè messa in produzione, del sito.
Analizziamo lo stage di build.
build:
stage: build
image: jojomi/hugo
script:
- hugo version
- git submodule update --init --recursive
- hugo -d public_html --gc --minify
artifacts:
paths:
- public_html
only:
- master
Ho scelto di utilizzare il container jojomi/hugo perchè, facendo qualche ricerca, è il più aggiornato. Nel momento in
cui scrivo questo articolo l’ultimo aggiornamento risale a 7 giorni fa.
Ho detto alla pipeline di eseguire questa operazione solo sulla branch master del mio repository:
only:
- master
Organizzo sempre i miei repository con almeno 2 branch, una branch dev, dove faccio esperimenti e modifiche, e
poi la branch master che contiene la release da portare in produzione.
Quindi lavoro sempre su altre branch e, nel momento in cui devo apportare le modifiche al sito che è online,
mergio in master.
Con il tag script definisco quali comandi deve lanciare il container per generare le pagine HTML ed infine con
artifacts esporto la cartella public_html che verrà passata alla prossima fase della pipeline.
script:
- hugo version
- git submodule update --init --recursive
- hugo -d public_html --gc --minify
artifacts:
paths:
- public_html
Al comango hugo questa volta ho passato 3 paramentri:
-d: serve a modificare la cartella di destinazione, quindi questa volta non creerà la cartellapublicmapublic_html;--gc: esegue alcuni task di pulizia (es.: cancellazione file di cache inutilizzati) appena finita la build;--minify: minifica i file che va a generare (HTML, XML etc.)
Se vuoi sapere in dettaglio quali sono tutti i parametri che puoi passare al comando hugo fai riferimento alla
documentazione:
qui
Siamo a metà dell’opera, passiamo al deploy.
Per ora, ho preferito inviare al server i file generati da Hugo tramite FTP, ma vorrei fare una versione 2.0
che utilizza rsync, anche per una questione di performance. Il trasferimento FTP l’ho gestito con il comando lftp.
Ho usato il container alpine, che è una distro linux molto leggera e, con il tag before_script,
ho installato lftp al suo interno.
deploy:
stage: deploy
image: alpine
before_script:
- apk update
- apk add lftp
script:
- lftp -e "set ftp:ssl-allow no; open $FTP_HOST; user $FTP_USER $FTP_PASSW; mirror -X .* -X .*/ --reverse --verbose --delete public_html/ ./; bye"
only:
- master
Anche questo stage è richiamato solo sulla branch master.
Il comando per la connessione FTP sembra complesso ed utilizza delle variabili di ambiente ($FTP_HOST, $FTP_USER
e $FTP_PASSW), te ne parlerò nel paragrafo successivo. Adesso ti spiego il funzionamento di lftp:
- il parametro
-edice adlftpquali comandi deve eseguire. I comandi devono essere inseriti in una stringa; - la prima operazione che facciamo è aprire la connessione FTP con il comando
open, la variabile di ambiente$FTP_HOSTdeve contenere l’url o l’ip del tuo hosting; - dobbiamo fornire le credenziali di accesso, con il comando
userpassiamo username e password sempre tramite varibili di ambiente; - tutti i file vengono trasferiti con il comando
mirror; - infine chiudo la connessione con
bye.
Per il comando mirror c’è da fare qualche precisazione.
mirror -X .* -X .*/ --reverse --verbose --delete public_html/ ./
- con
-X .* -X .*/ho escluso dall’upload i file nascosti (es.: .git); - di default
mirrorpreleva i dati dal server remoto e li scarica in una cartella locale, senza il parametro--reversequindi andrebbe a prelevare i file dal server e me li ritroverei, alla fine del processo, nel container; - il
--verbosemi è servito solo per fare un pò di debug all’inizio, per testare che tutto andasse a buon fine, è opzionale, anzi ti consiglio di rimuoverlo dopo che hai visto come funziona; - con
--deletevado a rimuovere dal server i files che non sono più presenti nell’artefatto che ha generato Hugo, ad esempio un immagine o un css di troppo, risparimare un pò di spazio e fare pulizia fa sempre bene!
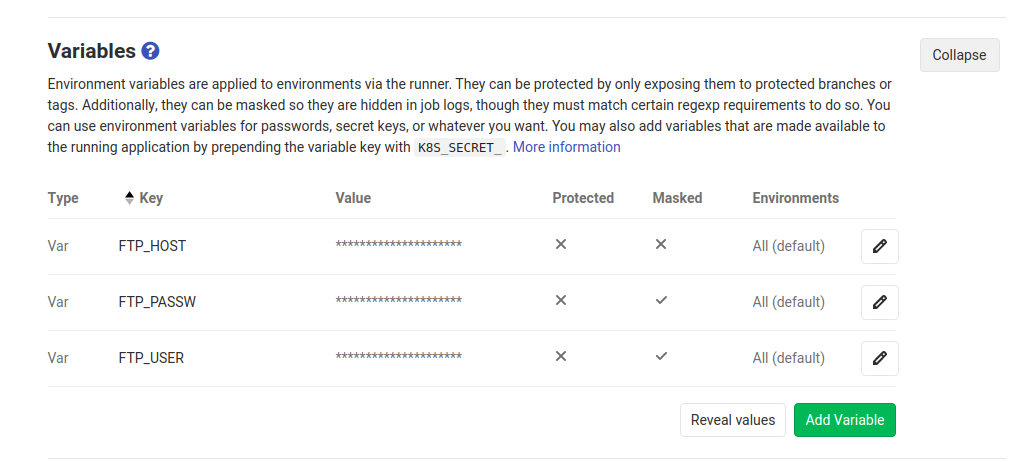
Variabili di ambiente
Non mi andava di inserire in chiaro sul reposotory dati sensibili, quindi ho impostato delle variabili di ambiente in Gitlab, le pipeline avranno accesso a tutte le variabili di ambiente che definisci. Ti lascio qualche screen per farti vedere dove si impostano le variabili:
Conclusioni
La pipeline che ho configurato per il deploy del sito mi fa risparmiare davvero tanto tempo. E poi.. vuoi mettere la soddisfazione di pushare tutto sul repository, spegnere il PC e ritrovarti, dopo qualche minuto, il sito aggiornato, senza aver toccato niente?
Puoi configurare delle pipeline per molti altri scopi, non ne ho parlato troppo in questo articolo ma puoi anche eseguire dei test in maniera automatica per capire se le modifiche che hai fatto al codice hanno rotto qualcosa 😄
Sei riuscito a configurare la tua pipeline? Scrivimi nei commenti
AP